-
ADsP - 확률분포S T U D Y/DataBase 2023. 1. 18. 20:43728x90반응형
이산형 확률분포
베르누이분포
- 실험 결과 두 가지 중의 하나로 나오는 시행의 결과를 0 또는 1의 값으로 대응시키는 확률변수 X에 대해 아래 식을 만족하는 확률변수 X가 따르는 확률분포
P(X=0) = p, P(X=1) = q, 0 <= p <= 1, q= 1-p
- 모수가 하나이며 서로 반복되는 사건이 일어나는 실험의 반복적 실행을 확률분포로 나타낸 것
- (예시) 동전을 던져서 앞면이 나올 확률, 주사위를 던져서 4의 눈이 나올 확률, 주사위를 던져서 4, 5의 눈이 나올 확률
- 베르누이 분포의 기대값은 p, 분산은 p*q 임.이항분포
- 서로 독립된 베르누이 시행을 n번 반복할 때 성공한 횟수를 x라 하면, 성공한 x의 확률분포를 말함.
- 확률변수 K가 n, p 두 개의 모수를 갖으며, K~B(n, p)로 표기함
- n = 1일 때 이항분포가 베르누이분포임.
- 이항분포의 기대값 E(x) = np
- 이항분포의 분산 : V(x) = np(1-p)
- (예시) 동전을 50번 던져 앞면이 나올 경우? n = 50, p = 1/2
주사위를 10번 던져서 나오는 눈이 5일 경우? n = 10, p = 1/6
타율 3할인 타자가 100번 타석에 ㄷ르어서면 안타를 얼마나 칠 것인가? n = 100, p = 0.3기하분포
- 베르누이 시행에서 처음 성공까지 시도한 횟수 X의 분포
포아송분포
- 단위 시간이나 단위 공간에서 어떤 사건이 몇 번 발생할 것인지를 표현하는 분포
- 특정 기간동안 사건 발생의 확률을 구할 때 쓰임
- (예시) 어떤 as 센터에 1시간당 평균 120건의 전화가 온다. 이 때 1분동안 걸려오는 전화 요청이 4건 이하일 확률
어느 가게에 1시간당 평균 8명의 손님이 온다. 이 때, 1시간 동안 손님이 10명 올 확률
확률은 x=람다에서 최대이고, x가 커질수록 0에 접근
연속형 확률분포
정규분포
- 가우스 분포라고도함
- 평균과 표준편차에 의해 모양이 결정됨
- 평균 0, 표준편차/분산 1인 정규분포 N(0, 1) 를 표준 정규분포, z 분포라고 함
- z분포의 평균 주위로 표준편차의 1배 범위에 있을 확률 68%, 2배 범위 안 95%, 3배 범위안 99.7%
- (예시) 키, 몸무게, 시험 점수 등 거의 대부분의 측정값이 정규분포를 따름확률밀도함수(Probability Desity Function, PDF)
- 특정 구간에 속할 확률을 계산하기 위한 함수
- 확률 밀도 함수, f(x)와 구간 [a, b]에 대해 확률변수 X가 구간에 포함될 확률
- 확률밀도 함수는 다음의 두 조건을 만족함
정규분포의 당위성(대부분의 측정값을 정규분포로 가정하는 이유)
이항분포의 근사 :
- 시행횟수 N이 커질 때, 이항분포 B(N, p)는 평균 Np, 분산 Npq인 정규분포와 N(Np, Npq)와 거의 같아짐
중심극한정리 :
- 표본의 크기가 N인 확률표본의 표본평균은 N이 충분히 크면 근사적으로 정규분포를 따르게 됨
- 모집단의 분포와 상관없이 표본의 크기가 30 이상이 되면 N이 커짐에 따라 표본평균의 분포가 정규분포에 근사해짐
오차의 법칙 :
- 오차(error) = e = x - m
- MLE(Maximum Likehood Estimator) : 실제 값일 가능성이 가장 높은 값
- 실제 값의 MLE가 측정값의 평균이라면, 오차는 정규분포를 따름지수분포
- 사건이 서로 독립적일 때 다음 사건이 일어날 때까지 대기 시간은 지수분포를 따름
T분포
- 정규분포는 표본 수가 적으면 신뢰도가 낮아짐 (n이 30 미만인 경우)
- 표본을 많이 뽑지 못하는 경우에 대한 대응책으로 예측범위가 넓은 분포를 사용하며, 이것이 T분포임.
- 표본의 개수가 많을수록 정규분포와 비슷하고, 적을 수록 옆으로 퍼짐
- 표본의 개수가 적을수록 신뢰도가 낮아지기 때문에 예측범윙를 넓히기 위해 옆으로 퍼지게 됨
- 30개 미만일 때 사용하므로, '신뢰구간', '가설검정'에 사용
- 그래프의 x축 좌표를 t값이라고 부름카이제곱분포
- 분산의 특징을 확률분포로 만든 것. 카이는 평균0, 분산1인 표준정규분포를 의미함
- 표준정규분포를 제곱한다는 의미를 가지고 있음
- 신뢰구간, 가설검정에 사용하고 그래프의 x축을 카이제곱값이라고 부름.
- 0이상의 값만 가질 수 있고, 오른쪽 꼬리가 긴 비대칭 모양
- 0의 오른쪽 부분에 분포가 많고, 0에서 멀어질수록 분포 감소
- 표본의 수가 많아지면 옆으로 넓적한 정규분포 형태가 됨
- 카이제곱분포의 특징이 곧 분산(치우침정도)의 특징F분포
- 카이제곱분포와 같이 분산을 다룰 때 사용함
- 카이제곱분포는 한 집단의 분산, F분포는 두 집단의 분산
- 두 집단의 분산이 크기가 서로 같은지 또는 다른지 비교하는데 사용
- 두 분산의 나눗셈을 확률분포로 나타낸 것이 F분포
- 표본의 수가 많아지면 1을 중심으로 정규분포 모양이 됨
- 분산 분석에 사용함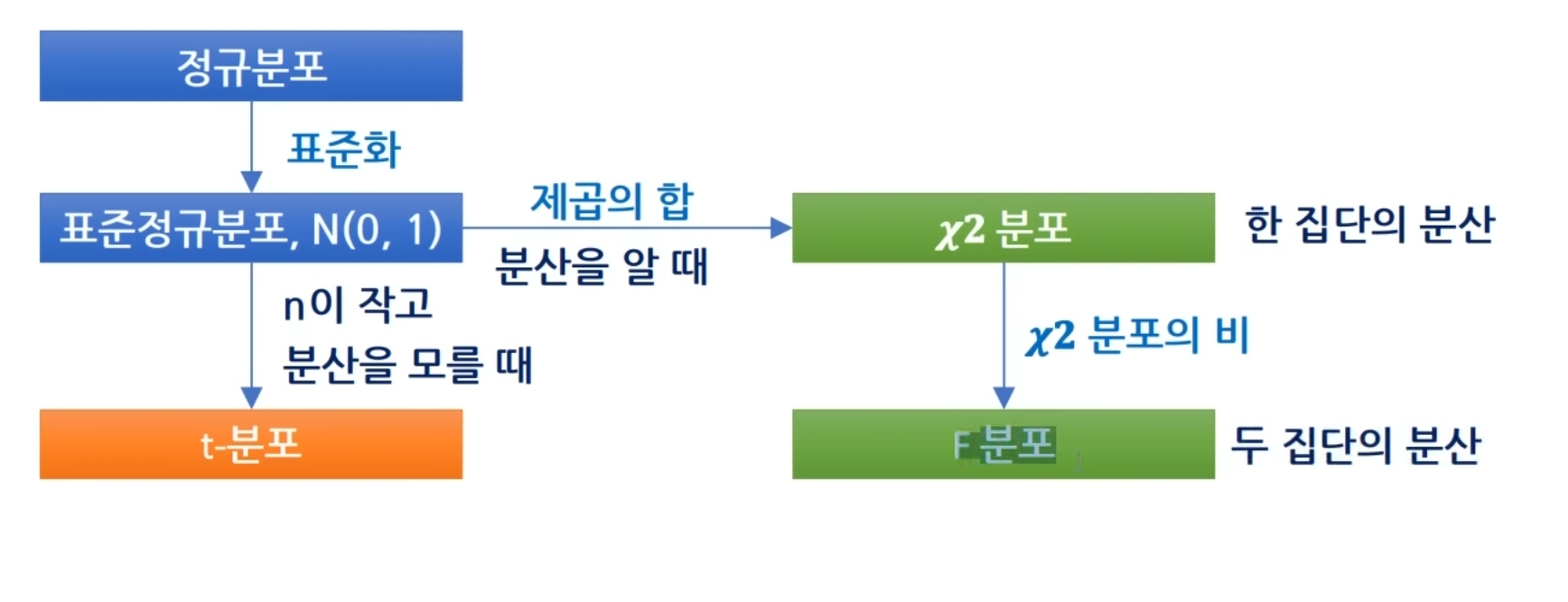
통계적 추론의 분류
모집단에 대한 가정 여부에 따른 통계적 추론의 분류
- 모수적 추론 : 모집단에 특정 분포를 가정하고 모수에 대해 추론
- 비모수적 추론 : 모집단에 대해 특정 분포 가정을 하지 않음
추론 목적에 따른 통계적 추론의 분류
- 추정 : 통계량을 사용하여 모집단의 모수를 구체적으로 추측하는 과정
ㄴ> 점추정 : 하나의 값으로 모수의 값이 얼마인지 추측함
ㄴ> 구간추정 : 모수를 포함할 것으로 기대되는 구간을 확률적으로 구함
가설검정 : 모수에 대한 가정을 세우고 그 가설의 옳고 그름을 확률적으로 판정하는 방법론
* 귀무가설,대립가설,유의확률 등의 의미에 대해 알아놓아야 함
모수처리 방식에 따른 통계적 추론의 분류
Frequentist
Bayesian
표준편차
: 자료가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 대표적 수치. 관측값 - 평균
표준오차
: 표본에서 전체 개체가 가지는 값들의 차이가 얼마나 큰지 나타냄

오차한계
: 추정을 할 때 모평균 추정구간의 중심으로부터 최대한 허용할 최대허용오차

좋은 추정량 판단 기준
- 일치성 : 표본의 크기가 커짐에 따라 표본 오차가 작아져야 함
- 비편향성, 불편성 : 편향 = 추정량의 기댓값 - 실제값(=모수의 값), 추정량의 기댓값이 모수의 값과 같아야 함
(편향==0)
- 효율성 : 추정량의 분산이 될 수 있는 대로 작아야 함(최소분산 추정량), MSE(Mean Square Error)가 작아야 함
통계적 추정점추정
- 모수가 특정할 값이라고 추정하는 것
점추정량 구하는 방법 :
- 적률법 : 표본의 기댓값을 통해 모수를 추정하는 방법
- 최대가능도추정법(최대우도법) : 함수를 미분해서 기울기가 0인 위치에 존재하는 MLE(Maximum likehood estimator) 를 찾는 방법
- 최소제곱법 : 함수값과 측정값의 차이인 오차를 제곱한 합이 최소가 되는 함수를 구하는 방법구간추정
신뢰구간 : 모수가 포함되리라고 기대되는 범위
신뢰수준 : 다수 신뢰구간 중 모수값을 포함하는 신뢰구간이 존재할 확률
신뢰수준 95% 의미 : n번 반복 추출해서 산정하는 신뢰구간 중에서 평균적으로 95%는 모수 값을 포함하고 있을 것이라는 의미
가설검정
귀무가설 : 연구자가 부정하고자 하는 가설
대립가설 : 연구자가 연구를 통해 입증 또는 증명되기를 기대하는 예상이나 주장
(예시)
범죄 사건에서 용의자가 있을 때 형사의 가설
귀무가설 : 용의자는 무죄이다
대립가설 : 용의자가 범죄를 저질렀다
제1종오류 : 귀무가설이 참인데 기각하는 오류. 불량이 아닌데 불량으로 만들어버리는 오류
제2종오류 : 귀무가설이 거짓인데 채택하는 오류. 불량품인데 불량이아니다 라고 하는 오류
두 가지오류가 작을수록 바람직한데 2종오류가 더 심각한 것임.
유의수준 : 제1종 오류의 최대 허용한계, 보통 유의수준 0.05를 사용함(100번 실험에서 1종오류 범하는 최대 허용한계가 5번)
유의확률(p-value)
- Probability value, 0<= p-value <=1, 1종 오류를 범할 확률, 귀무가설을 지지하는 정도
- 귀무가설이 사실일 때 기각하는 1종 오류 시 우리가 내린 판정이 잘못되었을 확률
- 검정 통계량들은 거의 대부분이 귀무가설을 가정하고 얻게 되는 값
- 검정 통계량에 관한 확률로 극단적인 표본 값이 나올 확률
- p-value가 작을수록 그 정도가 약하다고 보며, p-value < a 귀무가설을 기각하고 대립가설을 채택함.
- p-value가 0.05 (5%) : 귀무가설을 기각했을 때 기각 결정이 잘못될 확률이 5%임
귀무가설을 이용한 가설 검증 프로세스
모수적 추론
: 모집단에 특정 분포를 가정하고 분포의 특성을 결정하는 모수에 대해 추론하는 방법, n>30일경우 많이 사용
비모수적 추론
: 모집단에 대해 특정 분포 가정을 하지 않음. 모수 자체보다 분포 형태에 관한 검정 실시
표본 수가 적고, 명목척도, 서열척도인 경우(성별, 혈액형, 만족도, 메달 등)
n < 10일 경우 많이 사용.
n > 30 : 정규성 검정 없이 모수적 추론을 할 수 있음
10 <= n <= 30 : 정규성 검정을 한 뒤, 정규성을 갖는 경우 모수적 추론을 할 수 있고, 정규성 검정 없이 비모수적 추론이 가능함
n<10 : 비모수적 추론을 함
모수적검정 : 검정하고자 하는 모집단의 분포에 대해 가정하고, 가정하에 검정 통계량과 검정 통계량의 분포를 유도해서 검정을 실시
1) 가정된 분포의 모수에 대해 가설 설정
2) 관측된 자료를 이용해 구한 표본 평균, 표본 분산 등을 이용해 검정 실시
모수적 통계의 전제 조건 :
- 표본의 모집단이 정규분포를 이루어야 하고 집단 내의 분산은 같아야 함
- 변인(=변수)은 등간척도나 비율척도로 측정되어야 한다. 그게 아니면 비모수통계를 상ㅇ함.
모수 검정방법 :
- T test, Paried T test, Two sample T test, ANOVA test, z분포, t분포, F분포
모수 검정방법 사용 예 :
- 모평균과 표본평균과의 차이, 표본평균 간의 차이 : z분포, t분포
- 모분산과 표본분산과의 차이, 표본분산 간의 차이 : F분포
T-test
: 평균 값이 올바른지, 두 집단의 평균 차이가 있는지 검증하는 방법
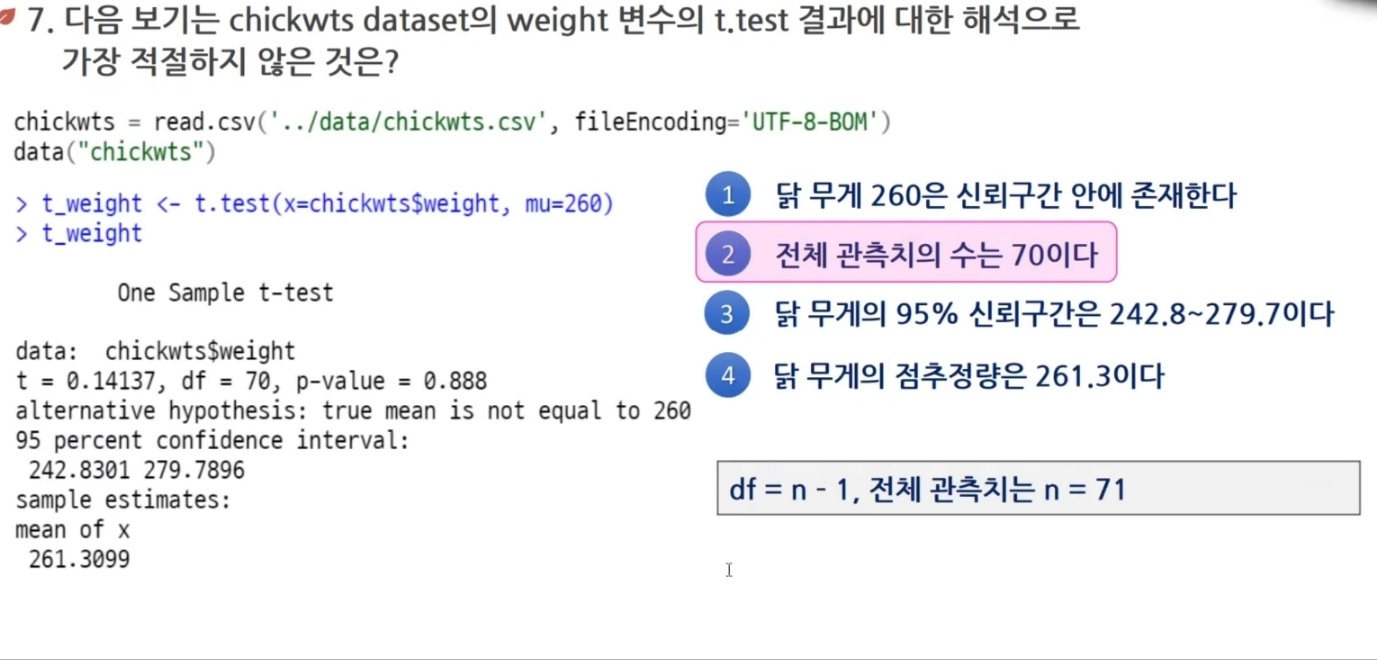
one sample test : 단일 표본의 평균 검정을 위한 방법
Paired t-test : 동일 개체에 어떤 처리를 하기 전, 후의 자료를 얻을 때 차이 값에 대한 평균 검정을 위한 방법
가능한 동일한 특성을 갖는 두 개체에 서로 다른 처리를 함
(예시) x질병 환자들을 두 집단으로 나눠서 A, B 약을 투약해 약의 효과를 비교함
Two sample t-test : 서로 다른 두 그룹의 평균을 비교해 두 표본의 차이가 있는지 검정하는 방법
귀무가설 - 두 집단의 평균 차이 값이 0이다
2학년과 3학년의 결석률은 같다
자유도
: 통계적 추정에서 표본자료 중 모집단에 대한 정보를 주는 독립적인 자료의 수
자유도 = 데이터 개수 - 1
one sample t-test
two sample t-test (=독립표본 t-test)
데이터의 정규성 검정 종류
Q-Q plot :
- 그래프 그려서 정규성 가정이 만족되는지 시각적으로 확인하는 방법
Histogram :
- 시각적으로 정규분포를 확인하는 방법
Shapiro-Wilk Test :
- 오차항이 정규분포를 따르는지 알아보는 검정
- 귀무가설은 정규분포를 따른다로 p-value가 0.05보다 크면 정규성을 가정하게 됨
kolmogorov-Smirnov test :
- K-S test, 두 모집단의 분포가 같은지 검정하는 것
- p-value가 0.05보다 크면 정규성을 가정하게 됨
앤더슨달링 :
비모수적 검정 : 분포형태에 대한 검정만 실시함.
모집단의 특성을 몇 개의 모수로 결정하기 어렵고 수 많은 모수가 필요할 수 있음
모수적 방법보다 훨씬 단순함
비모수적 검정의 종류 :
- 명목척도기준 : 카이스퀘어 검정
- 서열척도기준 : Sign Test
카이스퀘어검정 :
- 한 개 범주형 변수와 각 그룹별 비율과 특정 상수비가 같은지 검정하는 적합도 검정
- 각 집단이 서로 유사한 성향을 갖는지 분석하는 동질성 검정
- 두 개 범주형 변수가 서로 독립인지 검정하는 독립성 검정
부호검정(Sign Test) :
- 표본들이 서로 관련되어 있는 경우, 짝지어진 두 개의 관찰치들의 크고 작음을 +와 -로 표시해 그 개수를 가지고
두 그룹의 분포 차이가 있는가에 대한 가설을 검증하는 방법

 728x90반응형
728x90반응형'S T U D Y > DataBase' 카테고리의 다른 글
ADsP 데이터분석준전문가 3과목 matrix(행렬), array(리스트) 실행 예시 (2) 2023.01.25 Adsp 데이터분석준전문가 3과목 - 벡터 생성, 연산, 인덱싱, 벡터 결과값 예시 (0) 2023.01.25 ADsP 데이터 분석 - 통계분석 (0) 2023.01.17 adsp 3과목 - 데이터 분석 (0) 2023.01.17 Adsp - 데이터의 정의, 데이터의 유형, 암묵지와 형식지, DIKW, 데이터베이스, DBMS, 스키마와 인스턴스 (0) 2023.01.14