-
ADsP 데이터분석준전문가 - 인공신경망, 모형 평가 방법S T U D Y/DataBase 2023. 2. 5. 20:40728x90반응형
인공신경망 모형
분류 및 예측을 할 수 있음
분석가의 주관과 경험에 따름
풀고자하는 문제 종류에 따라 활성화 함수의 종류가 달라짐
역전파 알고리즘이 동일 입력층에 대해 원하는 값이 출력되도록 개개의 weight를 조정하는 방법으로 사용됨
이상치 잡음에 민감하지 않음
입력, 은닉, 출력층 3개의 층으로 구성돼있음
학습 : 입력에 대한 올바른 출력이 나오도록 가중치를 조절하는 것
bias, variance : 학습 알고리즘이 갖는 두 가지 종류의 error로 trade off 관계
- bias : 지나치게 단순한 모델로 인한 에러, bias가 크면 과소적합(underfitting)야기(=네트워크가 복잡한 의사결정 경계를 만들 수 없음)
- variance : 지나치게 복잡한 모델로 인한 에러, variance가 크면 과대적합(overfitting) 야기
- 학습모형이 유연하다는 것은 복잡도가 증가한다는 것을 의미함(bias가 낮고 variance가 높다는 뜻)경사하강법(Gradient descent)
함수 기울기를 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것
제시된 함수의 기울기의 최소값을 찾아내는 머신러닝 알고리즘
비용함수를 최소화하기 위해 파라미터를 반복적으로 조정하는 과정
1. 임의의 parameter 값으로 시작
2. cost function 계산, cost function은 모델을 구성하는 가중치 w 의 함수, 시작점에서 곡선의 기울기 계산
3. parameter 값 갱신 : W = W - learning rate * 기울기 미분값
4. n번의 iteration, 최소값을 향해 수렴함. learning rate가 적절해야 함신경망 모형의 장점
변수의 수가 많거나 입, 출력변수 간에 복잡한 비선형 관계에 유용
이상치 잡음에 대해서도 민감하게 반응하지 않음
입력변수와 결과변수가 연속형이나 이산형일 경우에도 모두 처리 가능신경망 모형의 단점
결과에 대한 해석이 쉽지 않음
최적의 모형을 도출하는 것이 상대적으로 어려움
모형이 복잡하면 훈련 과정에서 시간이 많이 소요됨
데이터를 정규화 하지 않으면 지역해(local maximum)에 빠질 위험이 있음신경망 활성화 함수
풀고자 하는 문제 종류에 따라 활성화 함수의 선택이 달라짐
목표 정확도와 학습시간을 고려해 선택하고 혼합사용도 가능
계단함수 : 0 또는 1 결과, 부호함수 : -1또는 1 결과, 선형함수 : y=xsigmoid 함수
연속형 0~1, logistic 함수라고 불리기도 함
선형적 멀티-퍼셉트론에서 비선형 값을 얻기 위해 사용softmax 함수
모든 logits의 합이 1이 되도록 output 정규화
결과가 다 범주인 경우 각 범주에 속할 사후확률을 제공하는 활성화 함수
주로 3개 이상 분류시 사용함신경망 은닉 층, 은닉노드
다층신경망은 단층신경망에 비해 훈련이 어려움
은닉층 수와 은닉 노드 수 결정은 분석가가 분석 경험에 의해 설정
은닉층 노드가 너무 적으면 underfitting 문제 발생
은닉층 노드가 너무 많으면 일반화가 어렵고, 레이어가 많아지면 소실문제 발생 가능, 과적합 문제 발생역전파 알고리즘
출력층에 제시한 값에 대해 실제 원하는 값으로 학습하는 방법으로 사용
출력층에서 입력층으로 오차 Gradient를 흘려보내면서 각 뉴런의 입력값에 대한 손실함수의 gradient를 계산기울기 소실 문제
다층신경망에서 은닉층이 많아 인공신경망 기울기 값을 베이스로 하는 역전파 알고리즘으로 학습시키려고 할 때 발생하는 문제
역전파알고리즘에서 계산된 gradient를 사용해 각 가중치 매개변수를 업데이트해줌
다층신경망에서는 역전파 알고리즘(Back-propagation)이 입력층으로 갈 수록 gradient가 점차적으로 작아져 0에 수렴해 weight가 업데이트 되지 않는 현상이 발생함. 이것이 기울기 소실
Activation function으로 sigmoid 함수 사용 시 발생 -> 해결 위해 ReLU등 다른 함수 사용모형평가
홀드아웃
원천 데이터를 랜덤하게 두 분류로 분리해 교차검정을 실시하는 방법
하나는 모형 학습 및 구축을 위한 훈련용자료, 하나는 성과평과를 위한 검증용 자료로 사용
잘못된 가설을 가정하게 되는 2종 오류의 발생을 방지함
idx <- sample(2, nrow(iris), replace=TRUE, prob=c(0.7, 0.3))
=> iris 데이터를 7:3 비율로 나눠 training에서 70%, testing 에 30% 사용하도록 하는 것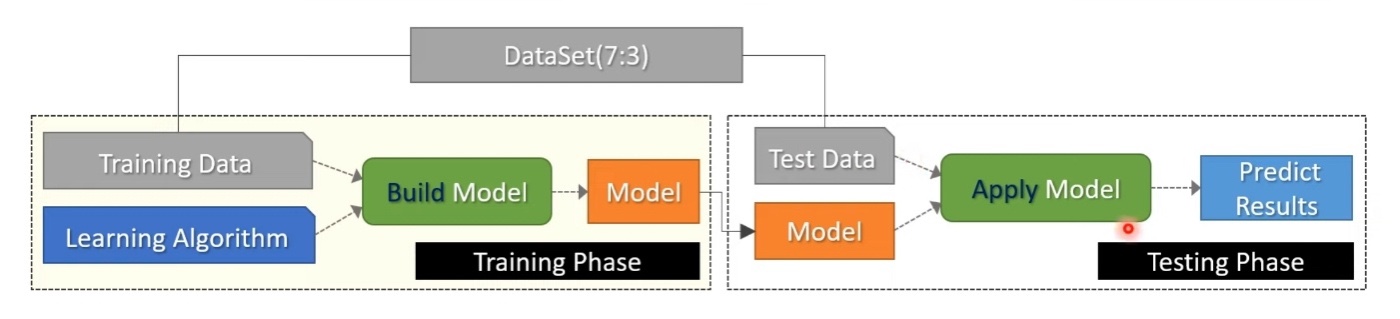
교차검증(Cross Validation)
데이터가 충분하지 않을 경우 hold out 으로 나누면 많은 양의 분산 발생하기 때문에 이에 대한 해결책으로 교차검증
그러나 클래스 불균형 데이터에는 적합하지 않음
<참고> 클래스 불균형 : 데이터 출력값이 한 쪽에 몰려있을 때. 암인사람90% 암이 아닌사람10%면 사용불가
주어진 데이터를 가지고 반복적으로 성과 추출해 그 결과 평균한 것으로 분류 분석 모형의 평가 방법
1. 전체 데이터를 섞음(shuffle)
2. K개로 데이터 분할
3. K번째의 하부 집합을 검증용 자료, K-1개는 훈련용 자료로 사용해 K번 반복 측정
4. 결과를 평균낸 값을 최종 결과로 사용함붓스트랩
교차검증과 유사하지만 훈련용 자료를 반복 재선정한다는 점에서 차이가 있음
관측치를 한 번 이상 훈련용 자료로 사용하는 복원추출법에 기반함
전체 데이터 양이 크지 않을 경우 모형 평가에 가장 적합
훈련 데이터를 63.2% 사용하는 0.632 붓스트랩이 있음데이터 분할 시 고려사항
class비율이 한 쪽에 치우쳐 있는 클래스 불균형 상태면 under sampling(적은 class수에 맞추는 것)
또는 over smapling(많은 수의 class 수에 맞추는 것)을 고려한다set.seed(1234)
: 랜덤한 수를 발생, 사용할 때 랜덤 수가 발생할 순서를 고정하는 것. 따라서 이 함수가 있으면 반복 수행하더라도 매회 동일한 데이터 분할이 샘플링됨
728x90반응형'S T U D Y > DataBase' 카테고리의 다른 글
[SQLP] SQLP 조사하기, 준비하기, 기출문제 사이트 (0) 2023.03.23 오분류표 (0) 2023.02.08 ADsP 데이터분석준전문가 - 앙상블, k-NN, SVM (0) 2023.02.05 ADsP 데이터분석준전문가 - 의사결정나무 (0) 2023.02.05 ADsP 데이터분석준전문가 - 데이터 마이닝, 데이터 분석 순서, 분류분석 종류 (0) 2023.02.05